Ajustement avec des données avec erreurs
Contents
Ajustement avec des données avec erreurs#
La minimisation du coefficient de détermination \(R^2\) défini de façon ad hoc permet d’estimer la valeur des paramètres d’un modèle à partir d’un jeu de données. Nous allons présenter ici d’autres quantités ayant des motivations probabilistes, notamment lorsque l’on peut associer à chaque mesure une erreur.
Vraisemblance et moindre carrés#
Une quantité d’intérêt est la fonction de vraisemblance 1. Considérons un jeu de données \(\{x_i\} _{i=1...N}\). On définit la fonction de vraisemblance \(\mathcal{L}\) des données sachant un modèle comme étant la probabilité d’obtenir toutes les données \(x_i\). Si \(p(x_i;\vec{\theta})\) est la probabilité d’obtenir la mesure \(x_i\) avec le jeu de paramètres \(\vec{\theta}\), la vraisemblance s’écrira donc:
On suppose toujours que les mesures sont indépendantes. Si les données sont placées dans un histogramme, les \(\{x_i\} _{i=1...N}\) sont le nombre de coups dans chaque bin, \(p\) sera une probabilité suivant la loi de Poisson avec \(\lambda\) la valeur attendue du bin prédite par le modèle et comme \(k\) le nombre d’évènements \(x_i\) dans le bin. Le nombre de coups attendus \(\lambda\) peut lui même suivre un autre modèle et dépendre d’autres paramètres.
Si les données sont des couples ou points \(\left(x_i, y_i\right)\) avec des erreurs \(\sigma _i\) sur les \(y_i\) et que l’on souhaite tester une relation entre \(X\) et \(Y\) (comme par exemple une dépendance linéaire \(Y=aX+b\)), les points de données sont dispersés normalement (selon une loi gaussienne) autour de la prédiction du modèle et la vraisemblance peut s’écrire comme:
avec \(\theta\) les paramètres du modèle à tester. Dans ce cas, le nombre de paramètres \(\vec{\theta}\) dépend de la complexité du modèle; les valeurs de \(\vec{\theta}\) qui maximisent \(\mathcal{L}\) est le meilleur modèle par rapport aux données collectées.
Ici on vient de calculer les paramètres qui rendent les données obtenues les plus probables pour un modèle donné.
On peut noter ici que puisque les probabilités \(p(x_i;\vec{\theta})\) de l’équation (70) sont plus petites que 1, la fonction de vraisemblance est plus petite que 1. Notamment, plus le nombre de points de données augmente, plus la vraisemblance est faible.
Dans le cas où on considère un modèle gaussien comme dans l’équation (71), on peut utiliser la fonction \(\ln\) pour simplifier le problème:
Le terme \(cste\) est bien une constante ne dépendant que des erreurs des points de données \(\sigma _i\). Le \(\chi^2\), aussi appelé moindre carrés, est la somme des écarts quadratiques entre le modèle et les données, pondérés par le carré inverse des incertitudes. Maximiser la vraisemblance (71) revient à minimiser le \(\chi ^2\) (72).
Notons que cela peut s’étendre aussi aux cas des distributions poissonniennes pour des données binnées puisque la distribution de Poisson tend vers une distribution gaussienne quand le nombre d’évènements attendu est “grand”; en pratique, pour \(\lambda \geq 25\).
Exercise 9
On réalise une trentaine de mesures d’une même grandeur. On obtient les résultats rangés dans la liste suivante:
valeurs = [ 9.19, 11.30, 4.21, 7.88, 7.60, 11.87, 10.53, 12.32, 10.64, 7.21,
7.73, 12.02, 12.93, 10.05, 13.15, 9.55, 10.81, 12.51, 7.44, 11.52,
11.55, 9.38, 6.70, 11.00, 13.48, 8.18, 7.43, 11.37, 13.09, 9.21 ]
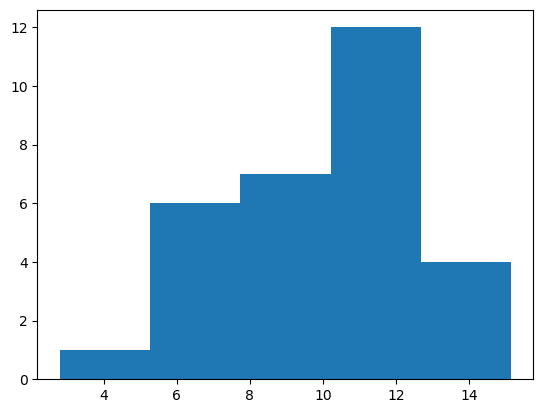
Ranger les valeurs dans un histogramme avec 5 bins. La région globale de l’histogramme est entre 2.8 et 15.15.
Calculer la vraisemblance des données en prenant comme modèle une loi normale d’écart-type 4 et centrée en 10. On pourra calculer le logarithme de la vraisemblance par commodité.
Calculer le logarithme de la vraisemblance des données en prenant comme modèle une loi normale d’écart-type 2.4 et centrée en 10. Comparer avec la valeur obtenue dans la question précédente. Quelle modèle vous semble plus correct?
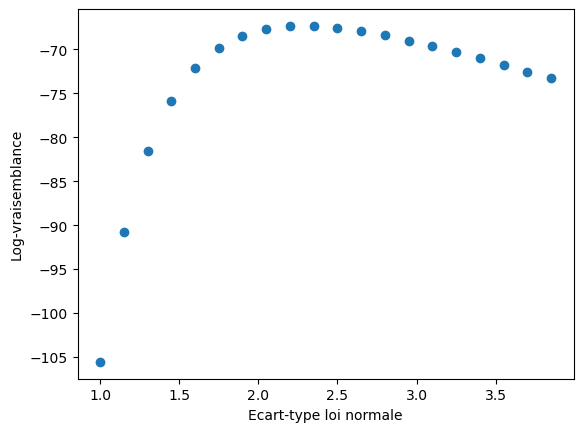
Tracer le logarithme de la vraisemblance en fonction de l’écart-type de la loi normale: on gardera la moyenne de la loi normale fixé à 10. Estimer la valeur optimale de l’écart-type de la loi normale.
Estimer la moyenne et l’écart-type de la population à partir de cet échantillon. Confirmer votre estimation de la question précédente.
Solution to Exercise 9
valeurs = [ 9.19, 11.30, 4.21, 7.88, 7.60, 11.87, 10.53, 12.32, 10.64, 7.21, 7.73, 12.02, 12.93, 10.05, 13.15, 9.55, 10.81, 12.51, 7.44, 11.52, 11.55, 9.38, 6.70, 11.00, 13.48, 8.18, 7.43, 11.37, 13.09, 9.21 ] import matplotlib.pyplot as plt fig, ax = plt.subplots() # creation d'un plot n, bins, _ = plt.hist(valeurs, bins=[2.8, 5.27, 7.74, 10.21, 12.68, 15.15])
from math import sqrt, exp, log def normale(x, moy, std): return 1/sqrt(2*3.14159)/std*exp(-(x-moy)**2/(2*std**2)) lnL = 0 for valeur in valeurs: lnL = lnL + log(normale(valeur, 10, 4)) print("lnL(10,4)=", lnL)
lnL = 0 for valeur in valeurs: lnL = lnL + log(normale(valeur, 10, 2.4)) print("lnL(10,2.4)=", lnL)
La vraisemblance a augmenté avec cette nouvelle valeur d’écart-type; ce nouveau modèle semble plus correct.
def logL(moy, std): lnL = 0 for valeur in valeurs: lnL = lnL + log(normale(valeur, moy, std)) return lnL v_std = [1.+ 3.*i/20 for i in range(0, 20)] v_logL = [logL(10, s) for s in v_std] fig, ax = plt.subplots() # creation d'un plot plt.plot(v_std, v_logL, "o") plt.xlabel("Ecart-type loi normale") plt.ylabel("Log-vraisemblance")
La valeur qui semble maximiser la vraisemblance est autour de 2.4.
import numpy as np valeurs = [ 6.967, 9.582, 14.881, 8.981, 4.385, 9.424, 14.381, 7.896, 10.867, 9.242, 8.430, 9.194, 9.417, 9.869, 12.418, 11.383, 10.119, 13.318, 11.134, 8.748, 12.624, 13.815, 12.745, 7.874, 10.923, 8.243, 8.596, 6.824, 12.765, 10.988 ] moyenne = np.mean(valeurs) stdev = np.std(valeurs) print("Moyenne = {0:.3f}".format(moyenne)) print("Ecart-type = {0:.3f}".format(stdev))
La valeur de l’écart-type trouvée ici est très proche de la valeur estimée dans la question précédente.
lnL(10,4)= -74.03191478477355
lnL(10,2.4)= -67.37370718290495
Moyenne = 10.201
Ecart-type = 2.402
Extraction des meilleurs paramètres#
Trouver les meilleurs paramètres d’un modèle selon les données collectées revient à maximiser la vraisemblance ou bien minimiser le \(\chi ^2\).
Cela peut se faire numériquement, par exemple, avec le module scipy.optimize ou bien analytiquement: en généralisant pour des paramètres \(\vec{\theta}\), le système d’équations à résoudre est 2:
En particulier, pour des modèles qui dépendent linéairement de ses paramètres comme par exemple \(f(x) = ax+b\) ou \(f(x) = a\sin x + be^x\), on peut résoudre le système:
pour \(\hat{a}\) et \(\hat{b}\) les paramètres optimaux du modèle.
Cas d’un ajustement linéaire#
Dans le cas fréquent où \(f(x) = ax+b\), on peut résoudre le système en posant:
La solution est alors:
Dans le cas où \(f(x) = ax\), l’expression du meilleur paramètre \(\hat{a}\) se simplifie comme:
L’utilisation des librairies externes permet de réaliser des ajustements plus complexes qui ne possèdent pas de solution analytique; il est cependant important de les comparer avec des relations analytiques (“benchmarking”) afin de vérifier que les résultats donnés correspondent à ce que l’on attend.
Extraction de l’incertitude sur un paramètre#
Lorsqu’on ajuste un modèle à des données expérimentales, il ne suffit pas de déterminer les meilleurs paramètres (ceux qui minimisent le \(\chi^2\)). Il est tout aussi important d’estimer les intervalles de confiance associés à ces paramètres. Ces intervalles indiquent la plage de valeurs dans laquelle le paramètre a une certaine probabilité de se trouver, en tenant compte des incertitudes expérimentales.
L’incertitude sur un paramètre est définie en terme de probabilité d’obtenir la vraie valeur à partir des données mesurées: il faut intégrer la fonction de vraisemblance sur l’intervalle de confiance définit par la valeur moyenne \(\theta\) et l’incertitude \(\sigma_{\theta}\) sur le paramètre~: \(\left[\theta-\sigma_{\theta},\theta+\sigma_{\theta}\right]\). En général, c’est un travail très complexe car la fonction de vraisemblance peut contenir des densité de probabilité complexe à écrire et intégrer; de plus, le nombre de dimensions à intégrer est égal au nombre de paramètres du modèle, rendant le calcul impraticable lorsque le nombre de paramètres est très grand. Cependant, pour des modèles simples comme des modèles linéaires avec des distributions gaussiennes des données, il est possible de calculer les incertitudes sur les paramètres en utilisant le \(\chi ^2\) (72).
En l’absence de corrélation entre les paramètres ajustés, l’incertitude à \(1\sigma\) sur un paramètre s’obtient empiriquement en trouvant l’excursion \(\Delta\) de la valeur de ce paramètre telle que le \(\chi^2\) augmente d’une unité, les autres paramètres étant fixés à la valeur optimale (qui minimise le \(\chi^2\)). Si le coefficient de corrélation \(\rho\) entre les paramètres n’est pas nul, cette excursion vaut \(\Delta = \sigma \sqrt{1-\rho^2}\). Pour un ajustement linéaire, la corrélation entre la pente \(a\) et le piédestal \(b\) est nulle si la moyenne des abscisses pondérées par les variances inverses est nulle. On peut toujours s’y ramener par un changement d’origine des abscisses.
Application aux paramètres d’un ajustement linéaire
Dans le cas simple d’un ajustement linéaire \(y=ax+b\), les incertitudes sur les paramètres \(a\) et \(b\) sont définies par:
Graphiquement, on peut construire ces intervalles comme sur le graphique ci-dessous~: le minimum de la courbe de \(\chi^2\) est en \(a=2\) et l’incertitude à \(1\sigma\) (correspondant à un niveau de confiance de \(68.3\%\)) se construit en déterminant les abscisses des points d’intersection de la courbe \(\chi^2\) avec la courbe \(y=\chi^2_{\mathrm{min}}+1\).
import matplotlib.pyplot as plt
import numpy as np
def parabola(x):
return 1.5+0.8*(x-2)**2
list_x = np.linspace(-1,5)
list_y = parabola(list_x)
plt.plot(list_x,list_y)
# minimum of the curve
plt.hlines(1.5,-1,2,linestyles="dashed",colors="green")
plt.vlines(2,0,1.5,linestyles="dashed",colors="green")
plt.text(-1.5,1.5,r"$\chi^2_{\mathrm{min}}$",color="green")
plt.text(2+0.1,0.2,r"$a_{\mathrm{min}}$",color="green")
# error on the curve
plt.hlines(2.5,-1,2+1/np.sqrt(0.8),linestyles="dashed",colors="orange")
plt.vlines(2-1/np.sqrt(0.8),0,2.5,linestyles="dashed",colors="orange")
plt.vlines(2+1/np.sqrt(0.8),0,2.5,linestyles="dashed",colors="orange")
plt.text(-1.7,2.5,r"$\chi^2_{\mathrm{min}}+1$",color="orange")
plt.text(2-1/np.sqrt(0.8)-0.8,0.2,r"$a_{\mathrm{min}}-\sigma_a$",color="orange")
plt.text(2+1/np.sqrt(0.8)+0.1,0.2,r"$a_{\mathrm{min}}+\sigma_a$",color="orange")
plt.grid()
plt.xlim(-1,5)
plt.ylim(0,7)
plt.xlabel(r"$a$")
a= plt.ylabel(r"$\chi^2$")
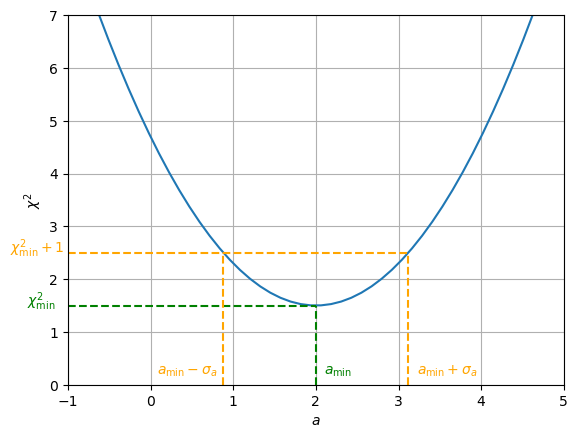
Ces erreurs valent:
Exemple: Ajustement linéaire simple – suite et fin
En reprenant les données dans la table Jeu de données linéaires, on peut calculer les incertitudes en utilisant les relations (77) et (78).
import numpy as np
x = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0])
y = np.array([1.2, 1.6, 1.7, 2.2, 2.3, 2.4, 3.1, 3.3, 3.1, 3.7])
err_y = np.array([0.2, 0.3, 0.3, 0.3, 0.3, 0.3, 0.4, 0.4, 0.4, 0.4])
from math import sqrt
# relations analytiques
B = 0
E = 0
for i in range(len(x)):
B += x[i]*x[i]/(err_y[i]*err_y[i])
E += 1./(err_y[i]*err_y[i])
a_error2 = 1/sqrt(B)
b_error2 = 1/sqrt(E)
print("Erreur sur a: {:.4f}".format(a_error2))
print("Erreur sur b: {:.4f}".format(b_error2))
Erreur sur a: 0.0187
Erreur sur b: 0.0973
L’incertitude sur \(a\) correspond à un intervalle à 68.3 % autour de la meilleure valeur de \(a\) (ici, 0.27). De par sa définition (76), cette erreur ne prend pas en compte la corrélation avec le coefficient \(b\).
Il est important de toujours comparer le résultat et notamment les erreurs données par un algorithme ou une librairie au résultat donné par la méthode analytique afin de vérifier que les conventions sont identiques.
Ajustement d’un histogramme#
Lorsque les données suivant une certaine loi de probabilité \(f(x;\vec{\theta})\) sont rangées dans un histogramme, il est possible d’estimer les paramètres de cette densité de probabilité. Pour cela on construit la fonction de vraisemblance (70) en supposant que le contenu de chaque classe \(N_i\) est distribué selon une loi poissonienne autour de la valeur vraie \(f(x_i;\vec{\theta})\times \delta x\) où \(x_i\) représente le centre de la classe et \(\delta x\) la largeur de la classe: on a alors
Dans le cas où le nombre de coups dans chaque classe est grand (\(N_i>25\)), on peut faire l’approximation de la densité de Poisson par une loi normale d’écart type \(\sigma _i = \sqrt{N_i}\). La maximisation de la fonction de vraisemblance est alors la minimisation du \(\chi ^2\):